LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models
17 Oct 2024 |
Daily Paper
하루에 한 논문을 30분 안에 간단하게 살펴본 결과를 기록하는 포스트입니다.
논문을 살펴볼 때 ChatGPT의 도움을 적극적으로 받으며, 따라서 포스트에 잘못된 내용이나 오류가 있을 수 있습니다.
피드백이나 의견 있으시면 언제든지 연락주세요.
3줄 요약
- Gen AI를 통해 합성/생성된 데이터를 판단하는 것에 LLM을 사용하면 설명을 제공할 수 있어 설명 가능성 (explainability) 측면에서 장점이 있다
- LOKI는 합성 데이터 탐지의 벤치마크 테스트로, 모델이 다양한 데이터(비디오, 오디오, 3D 모델, 이미지, 텍스트)에 대해 어떻게 판단하는지 종합적인 분석이 가능하다
- 현 시점의 주요 모델들은 합성 데이터 탐지에서 일정 수준의 성과를 보였으나, 여전히 인간 성능에 미치지 못하는 부분이 많다
LOKI?
- 다양한 모달리티를 가진 합성 데이터를 탐지하기 위한 벤치마크 테스트
- AI가 만든 합성 데이터를 얼마나 잘 구별할 수 있는지를 평가하는 테스트 도구
주요 특징
- Multimodal Data:
- 비디오, 이미지, 3D, 텍스트, 오디오 같은 여러 가지 종류의 데이터를 다룹니다. 즉, 하나의 모델이 이 모든 종류의 데이터를 보고 진짜인지 가짜인지 구별해야 한다는 뜻입니다.
- 예를 들어, AI가 만든 가짜 비디오나 이미지, 또는 AI로 생성된 가짜 텍스트 등을 탐지할 수 있는지를 평가합니다.
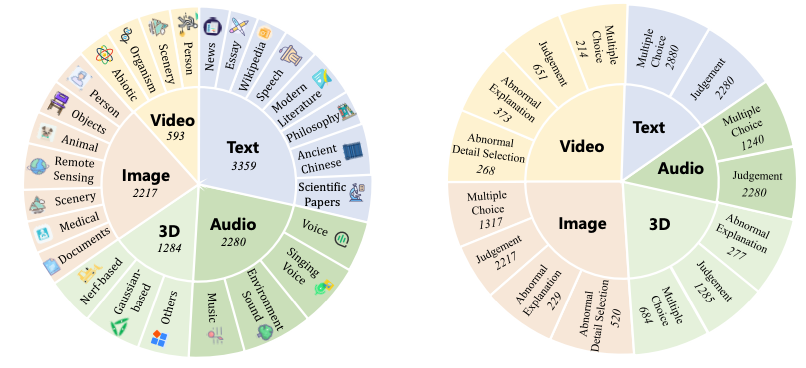
- Diverse Categories:
- 26개의 세부 카테고리(subcategories)로 나뉘어져 있어서, 단순한 이미지나 텍스트뿐만 아니라 위성 이미지, 의료 이미지, 음악, 환경 소리와 같은 더 전문적인 데이터도 포함하고 있습니다.
- Multi-level Annotations:
- 데이터에 대한 기본적인 “Real or Fake” 같은 단순한 질문뿐만 아니라, 왜 그 데이터가 가짜인지 이유를 설명(explanation tasks)해야 하는 복잡한 질문도 포함됩니다. 이를 통해 모델의 explainability를 테스트할 수 있습니다.

- 데이터에 대한 기본적인 “Real or Fake” 같은 단순한 질문뿐만 아니라, 왜 그 데이터가 가짜인지 이유를 설명(explanation tasks)해야 하는 복잡한 질문도 포함됩니다. 이를 통해 모델의 explainability를 테스트할 수 있습니다.
- Comprehensive Evaluation:
- 단순히 하나의 모달리티에서 성능을 평가하는 것이 아니라, 비디오, 텍스트, 3D, 이미지 등 여러 가지 데이터를 종합적으로 평가합니다. 즉, 모델이 multimodal 환경에서 얼마나 잘 작동하는지를 보는 것이죠.
주요 모델의 결과
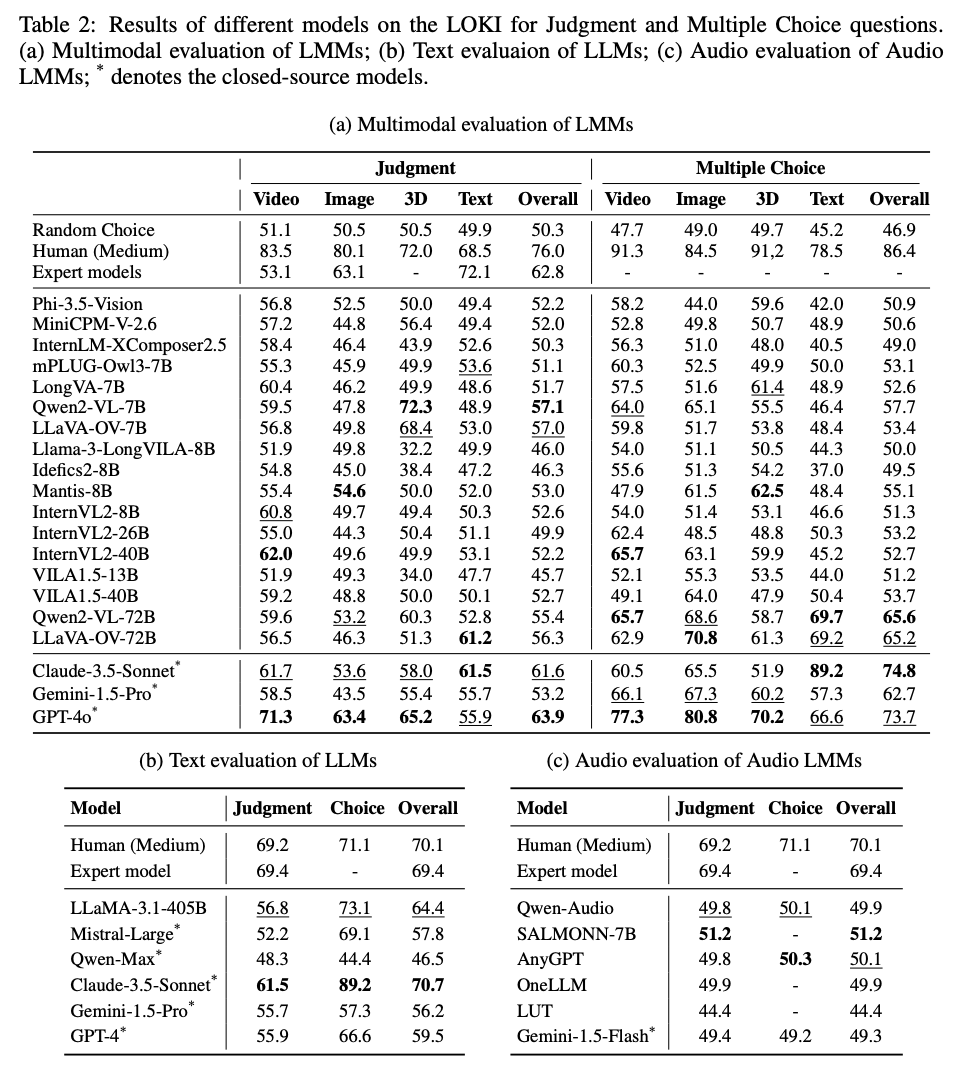
- 22개의 오픈소스 LMM과 6개의 비공개 상용 모델을 평가
- 영상, 이미지, 3D, 텍스트, 오디오 등 다양한 모달리티에서 성능을 측정
- Judgment tasks(합성 데이터인지 여부를 판단하는 작업)와 Multiple choice tasks(다중 선택 질문)를 수행
- 인간과의 비교
- 전반적으로 인간보다 낮은 성능. 특히 3D 및 오디오 모달리티에서 인간 성능에 비해 크게 미치지 못함
- 인간의 성능을 기준으로 easy, medium, hard 난이도로 질문이 구분되었으며, 대부분의 모델들은 easy 난이도에서만 인간에 근접한 성과
- 주요 모델들의 성능
- GPT-4o(비공개 모델)는 전체적으로 가장 높은 성능을 보였으며, 특히 텍스트와 이미지 모달리티에서 뛰어난 정확도를 기록
- Qwen2-VL-72B(오픈소스 모델)은 다양한 모달리티에서 고른 성능을 보였으며, 특히 Multiple choice tasks에서 좋은 성과
- Claude-3.5-Sonnet와 Gemini-1.5-Pro와 같은 비공개 상용 모델들도 높은 성능을 기록했습니다. 특히 Claude-3.5는 텍스트 모달리티에서 강세
- LOKI로 보는 현재 주요 모델의 문제점
- 모델 편향(bias)
- 많은 모델들이 특정 유형의 데이터를 선호하는 경향
- 특히 합성 데이터를 더 자주 진짜로 판단하는 모델 편향이 존재
- 특수 분야에서의 한계
- 위성 이미지나 의료 이미지와 같은 전문 데이터에서는 대부분의 모델들이 성능이 저조
- 모달리티 간 불균형
- 모델들은 이미지와 텍스트 작업에서는 비교적 좋은 성과를 보였으나, 3D 및 오디오 모달리티에서는 성능이 저조
- 모델 편향(bias)
Abstract
AI 생성 콘텐츠의 급속한 발전으로, 미래의 인터넷은 합성 데이터로 넘쳐나게 될 것이며, 진짜와 신뢰할 수 있는 멀티모달 데이터를 구별하는 것이 점점 더 어려워질 것입니다. 이로 인해 합성 데이터 탐지에 대한 관심이 높아졌으며, 대규모 멀티모달 모델(LMM)이 이 작업에서 어떻게 성과를 내는지에 대한 연구도 활발해졌습니다. LMM은 합성 콘텐츠의 진위 여부를 판단할 때 자연어로 설명을 제공할 수 있어, 탐지 결과의 설명 가능성을 높입니다. 동시에, 진짜와 합성 데이터를 구별하는 작업은 LMM의 지각, 지식, 추론 능력을 시험하는 좋은 기회가 됩니다.
이에 대응하여, 우리는 LMM이 여러 모달리티에서 합성 데이터를 탐지하는 능력을 평가하기 위한 새로운 벤치마크인 LOKI를 소개합니다. LOKI는 비디오, 이미지, 3D, 텍스트, 오디오 모달리티를 포함하며, 26개 세부 카테고리에서 난이도가 명확한 18,000개의 신중하게 선별된 질문으로 구성됩니다. 이 벤치마크는 기본적인 진위 판단과 다중 선택 질문뿐만 아니라, 세부적인 이상 선택과 설명 작업도 포함하여 LMM을 종합적으로 분석할 수 있게 합니다.
우리는 22개의 오픈소스 LMM과 6개의 비공개 모델을 LOKI에서 평가하여, 이들이 합성 데이터 탐지에서 잠재력을 가지고 있음을 확인하는 동시에, 현재 LMM의 성능 발전에 있어서 몇 가지 한계도 발견했습니다. 더 자세한 정보는 LOKI 웹사이트에서 확인할 수 있습니다.
목차 및 요약
1. Introduction
- AI로 생성된 합성 콘텐츠가 급증하면서 이를 구별하는 작업이 중요해졌습니다.
- LOKI는 대규모 멀티모달 모델(LMM)이 합성 데이터를 얼마나 잘 탐지하는지 평가하기 위해 개발되었습니다.
2. Related Work
- 기존 합성 데이터 탐지 연구와 LMM의 발전을 개관합니다.
- 기존의 벤치마크는 설명 가능성과 모달리티 다양성에서 한계가 있었음을 지적합니다.
3. Dataset
- LOKI는 5가지 모달리티(비디오, 이미지, 3D, 텍스트, 오디오)에서 26개 세부 카테고리로 이루어진 18,000개 이상의 질문으로 구성된 벤치마크입니다.
- 합성 데이터와 실제 데이터의 구별을 위한 다양한 난이도의 질문이 포함되어 있습니다.
4. Experiment
- LOKI에서 평가된 22개의 오픈소스 모델과 6개의 상용 모델이 있습니다.
- 다양한 LMM의 성능을 인간과 비교하고, 평가 프로토콜을 설명합니다.
5. Synthetic Data Detection Results
- LMM들은 합성 데이터 탐지에서 일부 성과를 보였지만, 특히 3D와 오디오 모달리티에서는 성능이 저조했습니다.
- 몇몇 모델은 chain-of-thought prompting 기법을 사용했을 때 성능이 향상되었습니다.
6. Discussion and Conclusion
- LOKI를 통해 LMM의 성능을 종합적으로 평가한 결과, 인간보다 낮은 성능과 모달리티 간 성능 차이가 드러났습니다.
- LOKI 벤치마크는 향후 LMM 발전에 중요한 역할을 할 것으로 기대됩니다.