LLM×MapReduce: Simplified Long-Sequence Processing using Large Language Models
17 Oct 2024 |
Daily Paper
하루에 한 논문을 30분 안에 간단하게 살펴본 결과를 기록하는 포스트입니다.
논문을 살펴볼 때 ChatGPT의 도움을 적극적으로 받으며, 따라서 포스트에 잘못된 내용이나 오류가 있을 수 있습니다.
피드백이나 의견 있으시면 언제든지 연락주세요.
3줄 요약
- LLM의 제한된 문맥길이를 극복하기 위해 긴 문서를 작은 조각(chunk)로 나누어 개별적으로 처리하는 방법을 제안
- 조각 간 의존성, 조각 간 충돌 문제를 해결하기 위해 조각 간 의미를 전달하고 평가할 수 있는 방법을 제시
- 다른 LLM보다 좋은 성능을 보였으나, 긴 텍스트를 처리하는 벤치마크의 결과만을 담고 있으므로 추가 검증 필요
배경
- LLM은 다양한 복잡한 작업에서 뛰어난 성능을 보여주고 있음
- 하지만 LLM은 문맥 길이(context length)가 제한되어 있어, 긴 문서를 처리하기 어려움
- LLM의 계산 복잡도는 문맥 길이에 대해 이차적으로 증가(quadratic computational complexity)
- 적합한 훈련 데이터를 준비하는 것도 어려움
LLM×MapReduce
- 분할 정복(divide-and-conquer) 전략을 사용하여 긴 문서를 작은 조각(chunk)으로 나누어 LLM이 개별적으로 처리한 후, 각 중간 결과를 종합하여 최종 출력을 생성하는 방식
- 문서를 분할할 때 장기 의존 관계가 손상될 수 있다는 점이 키포인트
- 조각 간 의존성(Inter-chunk dependency)
- 중요한 정보가 여러 조각에 나뉘어 존재할 때, 이러한 정보를 통합하여 올바른 답을 도출해야 함
- 조각 간 충돌(Inter-chunk conflict)
- 서로 다른 조각에서 상충되는 정보가 있을 때, 이를 해결하여 최종 답을 일관성 있게 제시해야 함
- 조각 간 의존성(Inter-chunk dependency)
구조화된 정보 프로토콜(structured information protocol)
- 각 조각에서 얻은 정보를 구조화된 형태로 처리하여 중요한 정보와 그 정보를 도출한 과정을 명확히 전달하는 프로토콜
-
조각 간 의존성(Inter-chunk dependency)를 해결하는 방법
- 구성요소
- Extracted Information (추출된 정보)
- 사용자 질문에 관련된 핵심 데이터를 각 조각에서 추출한 것
- Rationale (추론 과정)
- 각 조각에서 해당 정보가 왜 추출되었는지, 그리고 해당 정보를 통해 어떤 결론에 도달했는지를 설명하는 과정
- Answer (답변)
- 각 조각에서 도출된 중간 답변
- 만약 해당 조각에서 유효한 정보가 없으면 “NO INFORMATION”이라고 출력
- Confidence Score (신뢰도 점수)
- 각 조각에서 도출된 답변의 신뢰도를 점수로 부여하여, 후속 단계에서 해당 답변의 신뢰성을 평가할 수 있도록 함
- Extracted Information (추출된 정보)
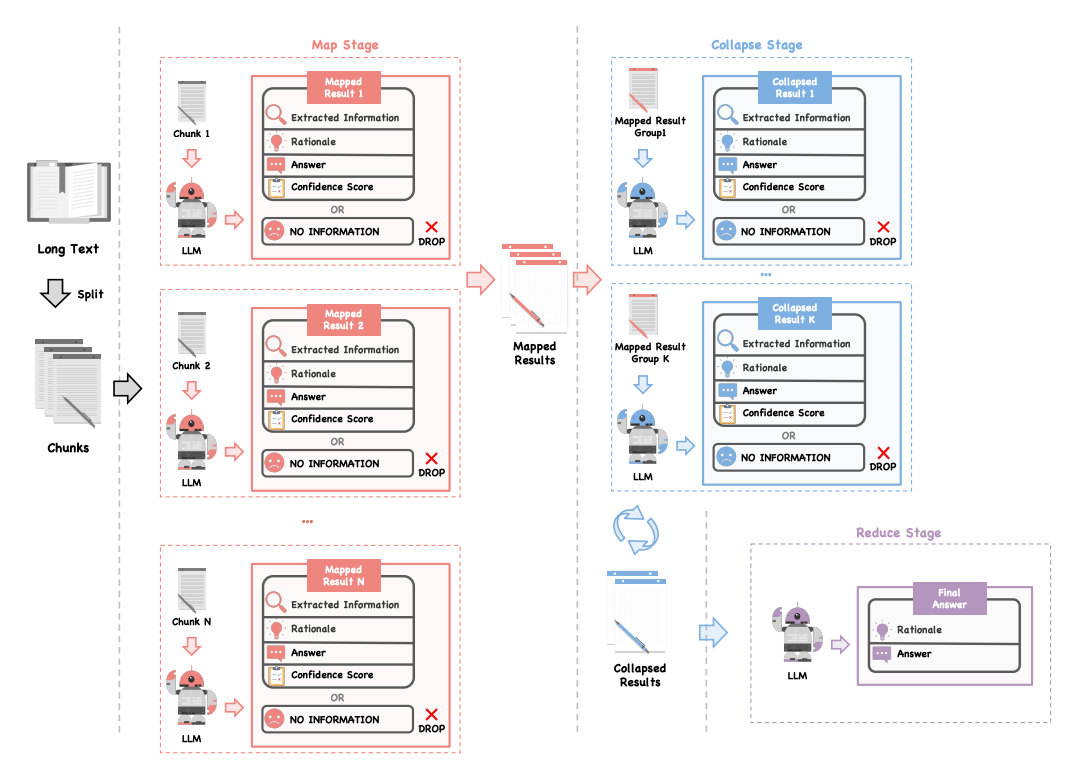
맥락 내 신뢰도 보정 메커니즘(in-context confidence calibration mechanism)
- 각 조각에서 도출된 정보에 대해 신뢰도 점수를 부여하는 메커니즘
-
조각 간 충돌(Inter-chunk conflict)를 해결하는 방법
- 원칙
- 고신뢰도 정보
- 주어진 텍스트에 명확하게 뒷받침되는 정보는 높은 신뢰도 점수를 획득
- 추론에 의한 정보
- 텍스트에서 명확히 언급되지 않았지만, 모델이 추론한 정보는 중간 수준의 신뢰도 점수를 획득
- 관련 없는 정보
- 텍스트와 관련이 없거나 잘못된 추론에 의한 정보는 낮은 신뢰도 점수를 획득
- 고신뢰도 정보
다른 모델과의 비교
- 벤치마크 : InfiniteBench
- 100,000토큰 이상의 매우 긴 텍스트를 처리하는 작업을 포함하며, 여러 작업(텍스트 이해, 정보 검색, 코드 이해, 수학 문제 해결 등)에 걸쳐 모델의 성능을 평가
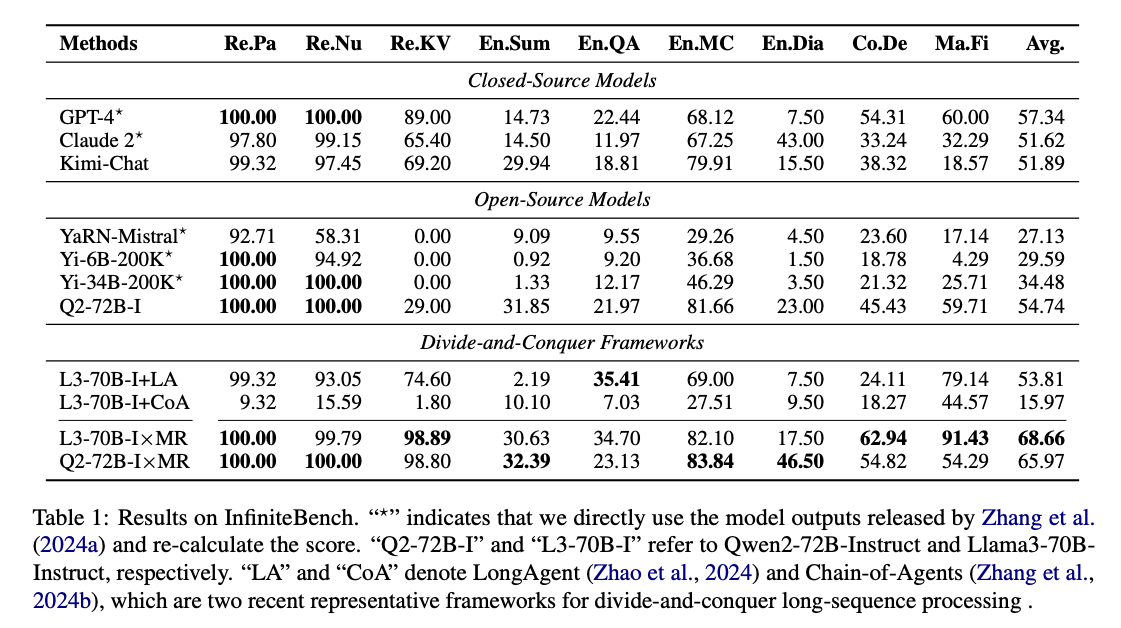
- LLM×MapReduce: 68.66점
- GPT-4: 57.34점 (상용 최고)
- Claude 2: 51.62점
- Kimi-Chat: 51.89점
- Qwen2-72B-Instruct: 54.74점 (오픈소스 최고)
Abstract
대형 언어 모델(LLM)의 문맥 창을 확장하는 것은 특히 매우 긴 텍스트를 다루는 응용 분야에서 중요한 연구 영역이 되었습니다. 이 논문에서는 긴 텍스트를 처리하기 위한 새로운 훈련이 필요 없는(framework-free) 프레임워크를 제안하며, 이를 분할 정복(divide-and-conquer) 전략을 활용하여 포괄적인 문서 이해를 달성합니다. 제안된 LLM×MapReduce 프레임워크는 전체 문서를 여러 조각으로 나누어 각 조각을 LLM이 읽도록 한 후, 중간 결과를 종합하여 최종 출력을 도출합니다. 긴 텍스트를 분할 정복 방식으로 처리할 때의 주요 과제는, 문서를 분할할 때 중요한 장기적인 정보가 손실될 위험이 있다는 점입니다. 이로 인해 모델이 분할된 텍스트만을 바탕으로 불완전하거나 잘못된 답변을 생성할 수 있습니다. 이러한 장기적 정보의 손실은 조각 간 의존성(inter-chunk dependency)과 조각 간 충돌(inter-chunk conflict)의 두 가지 유형으로 분류할 수 있습니다. 우리는 조각 간 의존성을 더 잘 처리하기 위해 구조화된 정보 프로토콜(structured information protocol)을 설계하고, 조각 간 충돌을 해결하기 위해 맥락 내 신뢰도 보정 메커니즘(in-context confidence calibration mechanism)을 도입했습니다. 실험 결과, LLM×MapReduce는 대표적인 오픈 소스 및 상용 장기 문맥 LLM보다 더 우수한 성능을 보였으며, 여러 다른 모델에 적용할 수 있음을 확인했습니다.
목차 및 요약
1. Introduction
- 긴 문서를 처리하는데 있어 LLM의 문맥 길이 제한 문제를 해결하기 위해, 훈련이 필요 없는 LLM×MapReduce 프레임워크를 제안합니다.
- 이 방법은 분할 정복 전략을 사용하여 긴 텍스트를 조각으로 나누고 결과를 종합하여 최종 답을 도출합니다.
2. Approach
2.1 Problem Description
- LLM의 문맥 창 한계를 넘어서는 긴 문서를 처리하기 위해, 문서를 여러 조각으로 나누어 처리한 후 이를 통합하는 방식이 필요합니다.
- 이 과정에서 발생하는 주요 도전 과제는 조각 간 의존성과 충돌 문제입니다.
2.2 Workflow of LLM × MapReduce
- 제안된 프레임워크는 세 단계(map, collapse, reduce)로 구성되며, 각 단계에서 정보를 추출하고 종합하여 최종 답을 도출합니다.
- 이 프레임워크는 각 조각에서 핵심 정보를 추출하고 이를 종합하여 긴 텍스트를 효과적으로 처리합니다.
2.3 Structured Information Protocol
- 조각 간 의존성을 해결하기 위해, 각 조각의 정보를 구조화된 형태로 저장하여 후속 단계에서 통합할 수 있도록 설계되었습니다.
- 이 구조화된 정보는 최종 답을 추론할 때 중요한 데이터를 전달합니다.
2.4 In-Context Confidence Calibration
- 조각 간 충돌을 해결하기 위해 각 조각에서 얻어진 결과에 신뢰도 점수를 부여하고, 이를 통해 충돌을 해결하여 최종 답을 결정합니다.
- 이 신뢰도 보정 메커니즘은 각 조각의 신뢰성을 일관되게 평가할 수 있도록 도와줍니다.
3. Experiments
3.1 Setup
- 제안된 프레임워크를 평가하기 위해 두 가지 오픈소스 모델(Llama3-70B-Instruct, Qwen2-72B-Instruct)을 사용했습니다.
- 다양한 벤치마크에서 실험을 수행하여 모델의 성능을 검증했습니다.
3.2 Main Results
- LLM×MapReduce는 기존의 상업적 및 오픈소스 LLM과 비교하여 더 나은 성능을 보였습니다.
- 특히 긴 문서 처리에서 효율성과 정확도에서 우수한 결과를 도출했습니다.
4. Conclusion
- LLM×MapReduce는 훈련이 필요 없는 긴 문서 처리 프레임워크로, 다양한 모델에서 성능을 입증했습니다.
- 이 방법은 기존의 긴 문서 처리 방식보다 더 높은 성능과 효율성을 제공합니다.