YOUR MIXTURE-OF-EXPERTS LLM IS SECRETLY AN EMBEDDING MODEL FOR FREE
18 Oct 2024 |
Daily Paper
하루에 한 논문을 30분 안에 간단하게 살펴본 결과를 기록하는 포스트입니다.
논문을 살펴볼 때 ChatGPT의 도움을 적극적으로 받으며, 따라서 포스트에 잘못된 내용이나 오류가 있을 수 있습니다.
피드백이나 의견 있으시면 언제든지 연락주세요.
3줄 요약
- LLM의 한계(인코딩 과정에 부적합)에 대한 연구가 활발히 일어나고 있음
- Mixture-of-Experts (MoE) 모델의 라우팅 가중치(Routing Weights, RW)가 대형 언어 모델(LLM)에서 임베딩 작업에 활용될 수 있음을 제안
- RW와 숨겨진 상태(Hidden State, HS)를 결합한 새로운 임베딩 방식(MOEE)이 다양한 임베딩 작업에서 성능을 향상시킴을 실험적으로 입증
논문 정보
- 논문 제목: Your Mixture-of-Experts LLM is Secretly an Embedding Model for Free
- 저자: Ziyue Li, Tianyi Zhou
- 소속: Department of Computer Science, University of Maryland, College Park
- 원문 링크: arXiv 링크
- 프로젝트 페이지: GitHub 링크
배경
- LLM의 발전과 한계
- LLM은 자연어 처리(NLP) 분야에서 생성 작업 (텍스트 생성, 번역 등)에서 뛰어난 성과
- 그러나 LLM은 임베딩(embedding) 작업에서는 성능이 제한적
- 주로 디코더 전용 아키텍처(decoder-only architecture)를 기반
- LLM의 숨겨진 상태(hidden state, HS)는 주로 다음 토큰을 예측하는 데 집중되어 있어, 임베딩에 필요한 전체적인 입력 정보를 포착하는 데 한계
- finetuning이 없을 경우, 임베딩 작업에 적합하지 않다는 평가
- Mixture-of-Experts(MoE) 모델
- 입력 데이터에 따라 가장 적합한 전문가(expert) 네트워크를 선택해 효율적으로 작업을 처리하는 신경망 아키텍처
- 최근에는 자연어 처리와 컴퓨터 비전 등 다양한 분야에서 대형 언어 모델(LLM)과 결합
- 아래와 같이 일반적인 HS LLM 모델과 비교하여 MoE LLM 모델이 성능이 좋은 결과를 볼 수 있음
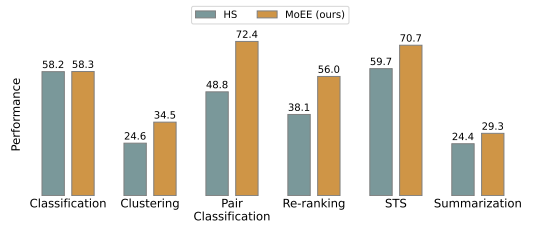
목적
- MoE LLM이 임베딩 작업에서 추가적인 미세 조정 없이도 고성능을 낼 수 있는지를 탐구
- LLM의 라우팅 가중치(Routing Weights, RW)가 숨겨진 상태(Hidden State, HS)와 어떻게 상호 보완적으로 작용할 수 있는지에 중점
- 이를 통해, LLM이 범용 모델로서 임베딩 작업에서도 활용될 수 있는지에 대한 의문을 해결하고자 함
MoE Routing Weights (RW) as Embedding
- MoE 모델의 핵심인 라우팅 가중치는 전문가(experts)들이 입력 데이터를 처리할 때, 각 전문가에게 할당되는 가중치를 결정하는 메커니즘
- 각 입력에 대해 라우터는 어떤 전문가가 어느 정도 기여할지를 결정하는 확률 분포(라우팅 가중치)를 생성
- 이 논문에서는 이 라우팅 가중치가 임베딩으로 사용될 수 있다고 제안
- RW는 각 층에서 입력에 대한 중요한 구조적 및 의미론적 정보를 포함하고 있음
- RW는 입력에 대한 고유한 처리 과정을 반영하여 기존의 LLM에서 HS만으로는 담기 어려운 정보를 캡처 가능
- RW는 HS보다 프롬프트에 덜 민감하고 더 높은 수준의 의미 정보를 포착하는 특성
Hidden State(HS) 와 Routing Weight(RW)
| 특성 | Hidden State (HS) | Routing Weight (RW) |
|---|---|---|
| 정의 | 신경망의 각 층에서 입력 데이터를 처리한 후 생성되는 중간 결과 | MoE 모델에서 라우터가 입력을 처리하기 위해 전문가에게 할당하는 가중치 |
| 역할 | 입력 데이터의 문맥적 정보를 담고, 다음 토큰 예측에 사용됨 | 입력을 특정 전문가에게 분배하는 역할, 입력의 특성을 반영한 가중치 |
| 주로 사용하는 모델 | GPT, LLaMA 등 일반적인 LLM에서 사용됨 | Mixture-of-Experts (MoE) 모델에서 사용됨 |
| 포착하는 정보 | 입력 시퀀스의 문맥적 의미와 생성 결과에 초점 | 입력 데이터의 구조적, 의미론적 특성 반영, 중간 추론 과정 강조 |
| 결합 방식 | 주로 마지막 층의 최종 HS를 임베딩으로 사용 | 모든 층의 RW를 통합하여 전체적인 입력 특징을 반영 |
| 프롬프트에 대한 민감성 | 프롬프트에 민감하며, 다양한 프롬프트에 따라 결과가 달라짐 | 프롬프트에 덜 민감하고 더 안정적인 정보 제공 |
The Proposed MoE Embedding (MOEE)
- HS와 RW는 상호보완적이며 두 방식의 결합이 더 나은 성능을 낼 수 있다
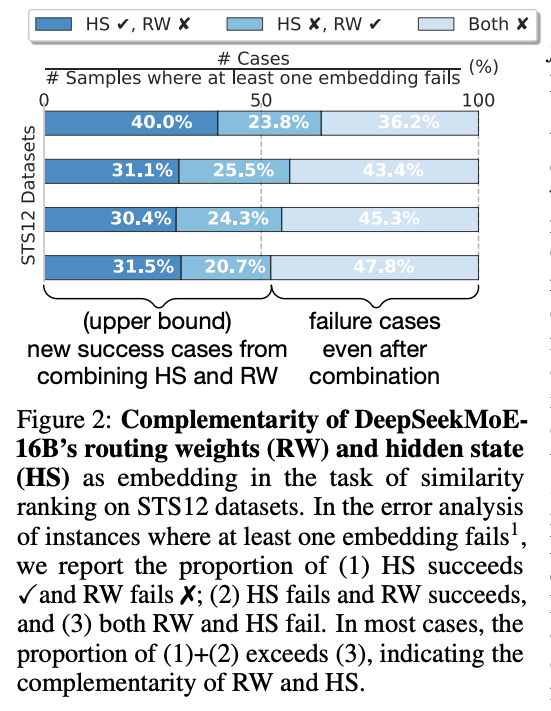
- RW와 HS를 결합한 새로운 임베딩 방법인 MoE Embedding (MOEE)를 제안
- Concatenation-based Combination (MOEE (concat))
- RW와 HS를 단순히 결합(concatenation)하여 하나의 임베딩으로 만드는 방식
- 이 방법은 RW와 HS가 개별적으로 제공하는 정보를 결합하여 더 풍부한 표현을 생성 가능
- Weighted Sum Integration (MOEE (sum))
- RW와 HS 간의 유사도를 각각 계산한 후 이를 가중합(weighted sum)하여 최종 유사도를 계산하는 방식
- 이 방법은 두 임베딩이 서로 다른 정보를 담고 있다는 점을 활용하여 출력에 의존적인 정보(Hidden State)와 입력에 민감한 정보(Routing Weights)를 균형 있게 통합
- 보통 이 방법이 가장 나은 성능을 보임
- Concatenation-based Combination (MOEE (concat))
Abstract
대형 언어 모델(LLM)은 생성 작업에서 뛰어난 성능을 보이지만, 디코더 전용 아키텍처는 추가적인 표현 미세 조정 없이는 임베딩 모델로서의 잠재력을 제한할 수 있습니다. 이는 이들이 범용 모델이라는 주장과 모순되는가요? 이 질문에 답하기 위해 Mixture-of-Experts(MoE) LLM을 면밀히 분석했습니다. 연구 결과, MoE LLM의 전문가 라우터가 추가적인 미세 조정 없이도 다양한 임베딩 작업에서 뛰어난 성능을 보이는 임베딩 모델로 활용될 수 있음을 확인했습니다.
추가 분석을 통해 MoE 라우팅 가중치(RW)가 LLM의 널리 사용되는 숨겨진 상태(HS)와 상호 보완적인 역할을 한다는 것을 발견했습니다. HS와 비교할 때, RW는 프롬프트 선택에 더 강인하며, 고수준의 의미론적 정보에 집중합니다. 이 분석을 바탕으로 RW와 HS를 결합한 MOEE를 제안하였으며, 이는 개별 사용보다 더 나은 성능을 보입니다. 특히, RW와 HS 유사도의 가중 합이 두 임베딩을 단순히 결합한 것보다 뛰어난 성능을 보여줍니다. 실험은 Massive Text Embedding Benchmark(MTEB)의 20개 데이터셋에 걸쳐 6가지 임베딩 작업을 수행했으며, MOEE는 추가 미세 조정 없이도 LLM 기반 임베딩 성능을 크게 향상시켰습니다.
목차 및 요약
1. Introduction
Mixture-of-Experts(MoE) 모델의 전문가 라우터가 임베딩 모델로 활용될 수 있음을 제시하며, HS와 RW가 상호 보완적인 역할을 한다고 주장합니다. 추가적인 미세 조정 없이도 높은 성능을 보여주는 MoE 임베딩(MOEE)을 제안합니다.
2. Related Work
기존 임베딩 기법과 MoE 구조의 관련 연구들을 검토합니다. LLM 기반 훈련 기법과 비훈련 임베딩 방법들의 성과를 비교합니다.
3. Mixture-of-Experts Embedding (MOEE)
MoE 라우팅 가중치(RW)와 숨겨진 상태(HS)를 결합해 임베딩 성능을 개선하는 방법론을 제시합니다. RW는 입력에 대한 세밀한 정보를 제공하며, HS는 문맥을 반영한 임베딩을 제공합니다.
3.1 MoE Routing Weights (RW) as Embedding
MoE 모델의 라우팅 가중치가 임베딩 역할을 할 수 있음을 설명하고, 이를 통해 생성된 임베딩의 특성을 논의합니다.
3.2 Comparative & Complementary Analysis of RW & HS
RW와 HS가 입력 데이터에서 서로 다른 정보를 캡처하는 것을 실험을 통해 분석합니다. 두 임베딩의 상호 보완적인 특성을 강조합니다.
3.3 The Proposed MoE Embedding (MOEE)
RW와 HS를 결합한 새로운 임베딩 방법인 MOEE를 제안하며, 성능 향상을 위해 다양한 결합 방식을 실험합니다.
4. Experiments
Massive Text Embedding Benchmark(MTEB)에서 다양한 임베딩 작업을 통해 MOEE의 성능을 평가합니다. 실험 결과 MOEE는 HS와 RW보다 일관되게 높은 성능을 보여줍니다.
4.1 Evaluation Setup
실험에 사용된 MoE 모델들과 각 작업에 대한 평가 설정을 설명합니다.
4.2 Main Results
MTEB 작업에서 MOEE가 HS나 RW만을 사용한 경우보다 우수한 성능을 보였다는 결과를 제시합니다.
4.3 Ablation Study
각 모델에서 RW와 HS를 어떻게 결합했는지에 따른 성능 변화를 분석합니다.
4.4 Stability Comparison of RW and HS Using Different Prompts
다양한 프롬프트를 사용했을 때 RW와 HS의 안정성을 비교합니다. RW는 프롬프트에 덜 민감하여 더 안정적인 성능을 보입니다.
5. Conclusion
MoE의 라우팅 가중치가 HS와 상호 보완적인 역할을 하여 임베딩 성능을 향상시킨다는 결론을 내립니다. MOEE의 잠재력을 강조하며 향후 연구 방향을 제시합니다.
잘 모르는 부분이 많은 논문이라 최대한 정리하였지만 한계가 많이 느껴짐
추가로 공부해야 할 것
- Embedding
- Hidden State