Differential Transformer
22 Oct 2024 |
Daily Paper
하루에 한 논문을 30분 안에 간단하게 살펴본 결과를 기록하는 포스트입니다.
논문을 살펴볼 때 ChatGPT의 도움을 적극적으로 받으며, 따라서 포스트에 잘못된 내용이나 오류가 있을 수 있습니다.
피드백이나 의견 있으시면 언제든지 연락주세요.
3줄 요약
- 두 Softmax Attention 맵을 계산한 후, 이를 서로 차감하여 최종 Attention Score를 계산하는 Diffrential Attention Mechanism을 제시
- 노이즈 제거, 긴 문맥 처리 능력 강화, 헐루시네이션 완화, In-context 학습 성능 향상, 모델 크기 효율성 등의 여러 면에서 기존 트랜스포머 모델에 비해 뛰어난 성능을 보임
- 조금의 변화로 큰 결과! (A slight change for huge results!)
논문 정보
- 논문 제목: Differential Transformer
- 저자: Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, Furu Wei
- 소속: Microsoft Research, Tsinghua University
- 원문 링크: arXiv 링크
Attention Mechanism
- 트랜스포머 모델의 핵심 구성요소
- 입력 시퀀스의 각 요소가 다른 요소들과의 관계(유사성)를 학습하는 방법
- 기본 개념
- Query(Q): 현재 처리 중인 토큰을 기준으로, 다른 토큰들과 얼마나 관련이 있는지를 묻는 질문.
- Key(K): 모든 토큰의 특징을 나타내며, Query와의 관련성을 평가하는 기준.
- Value(V): 각 토큰의 정보로, 실제로 사용할 데이터.
- 작동 과정
- Query와 Key 간의 유사성 계산:
- Query와 모든 Key 벡터 간의 내적(dot product)을 계산하여 관련성을 측정합니다. 이 값이 클수록 두 토큰 간의 유사성이 높습니다.
- Softmax 함수 적용:
- 유사성 점수에 Softmax 함수를 적용해 확률 값으로 변환하고, 이 값들이 어텐션 스코어가 됩니다.
- 이 스코어는 각 토큰이 다른 토큰에 얼마나 집중해야 하는지를 나타냅니다.
- Value 벡터의 가중합:
- 각 토큰의 Value 벡터에 해당 어텐션 스코어를 곱하여, 중요한 정보에 더 높은 가중치를 부여한 가중합을 계산합니다.
- 이 가중합이 최종 출력으로, 현재 토큰이 문맥 내 다른 토큰들과 상호작용한 결과를 반영합니다.
- Query와 Key 간의 유사성 계산:
- 종류
- 이 논문에 관련있는 종류만 설명함
- Softmax 어텐션
- 쿼리(Query)와 키(Key) 벡터 간의 내적(dot product)을 계산해 Softmax 함수를 적용함
- Scaled Dot-Product Attention
- Softmax 어텐션을 기반으로 한 변형
- 쿼리(Query)와 키(Key) 벡터의 내적을 계산한 후, 이를 벡터 차원의 제곱근으로 스케일링(scaling)하여 안정적인 학습
- Softmax를 적용하여 가중치를 계산한 후, 값(Value) 벡터에 가중합을 적용
- Multi Head Attention
- 여러개의 헤드가 독립적으로 어텐션 계산을 수행
- 모델이 다양한 관계나 패턴을 학습할 수 있으며, 여러 헤드에서 계산된 어텐션 값들은 결합되어 최종 출력
Differential Attention Mechanism
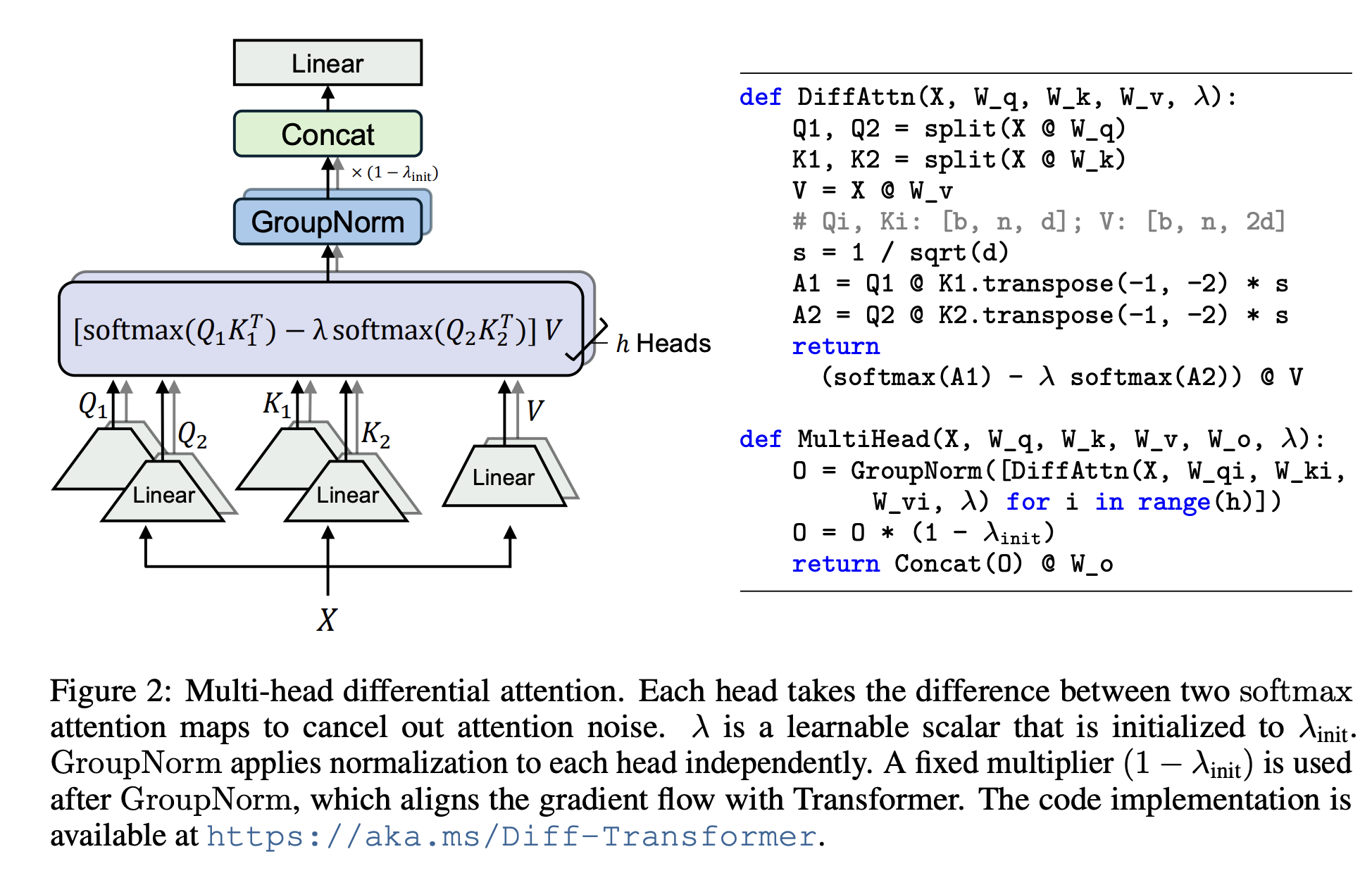
- 두 개의 Softmax Attention 맵 사용
- 두 개의 독립적인 Softmax Attention 맵을 계산
- 차감(Difference)을 통해 노이즈 제거
- 두 Softmax Attention 맵을 계산한 후, 이를 서로 차감하여 최종 Attention Score를 계산
- 이 차감 과정을 통해 공통된(즉, 중요하지 않은) 정보에 할당된 주의 점수가 제거되고, 중요한 정보에 더 많은 집중
- 멀티 헤드 어텐션을 적용하여 병렬적으로 DIFF 어텐션 학습 실행
장점
- 긴 문맥 처리 능력 개선
- 기존 트랜스포머는 문맥이 길어지면 불필요한 정보에 주의를 기울일 확률이 높아지는데, DIFF Transformer는 노이즈를 효과적으로 제거하여, 긴 문맥에서도 중요한 정보에 집중
- 64K 문맥 길이에서도 성능이 저하되지 않음
- 할루시네이션(Hallucination) 완화
- DIFF Transformer는 중요한 정보에만 집중하고 불필요한 정보에 대한 주의를 억제함
- In-context 학습 성능 및 강인성 향상
- In-context 학습이란, 모델이 주어진 문맥에서 중요한 정보만 학습하여 추론할 수 있는 능력
- DIFF Transformer는 문맥의 순서가 변경되었을 때도 더 강인한 성능을 보이며, 순서 변환에 덜 민감하게 동작
- 모델 크기와 학습 데이터 효율성
- DIFF Transformer는 모델 크기나 학습 토큰 수가 적더라도 기존 트랜스포머와 유사한 성능을 유지
- 실험 결과, 기존 트랜스포머가 요구하는 매개변수의 약 65%만으로도 유사한 성능을 달성
Abstract
트랜스포머(Transformer)는 관련 없는 문맥에 과도한 주의를 할당하는 경향이 있습니다. 이 연구에서는 DIFF Transformer를 소개하며, 이는 중요한 문맥에 대한 주의를 증폭시키고 노이즈를 제거합니다. 구체적으로, 차별적 주의 메커니즘은 두 개의 별도 소프트맥스 주의 맵 간의 차이를 계산하여 주의 점수를 산출합니다. 이러한 차감 방식은 노이즈를 제거하고, 희소한 주의 패턴이 나타나도록 유도합니다. 언어 모델링 실험 결과, DIFF Transformer는 모델 크기를 확장하거나 학습 토큰을 증가시킨 다양한 설정에서 기존 트랜스포머를 능가했습니다. 특히, 긴 문맥 모델링, 주요 정보 검색, 헐루시네이션 완화, In-context 학습, 활성화 아웃라이어 감소와 같은 실제 응용 분야에서 두드러진 장점을 보여줍니다. DIFF Transformer는 관련 없는 문맥에 덜 주의를 기울이기 때문에 질문 응답과 텍스트 요약에서 헐루시네이션을 완화할 수 있습니다. In-context 학습에서 DIFF Transformer는 정확성을 높일 뿐 아니라, 순서 변환에 대한 강인성도 높습니다. 이러한 결과들은 DIFF Transformer가 대형 언어 모델을 발전시키는 매우 효과적이고 유망한 아키텍처임을 보여줍니다.
목차 및 요약
1. Introduction
- Transformer의 주의력 할당 문제와 이를 해결하기 위한 새로운 차별적 주의 메커니즘을 제안함.
- DIFF Transformer는 불필요한 문맥 노이즈를 제거하고, 중요한 정보에 집중할 수 있도록 설계되었음.
2. Differential Transformer
- DIFF Transformer는 기존 트랜스포머와 유사한 구조를 가지지만, 주의 메커니즘에서 차별적 계산을 적용함.
- 차별적 주의는 두 개의 소프트맥스 주의 맵 간의 차이를 계산하여 노이즈를 제거함.
2.1 Differential Attention
- 차별적 주의는 두 개의 쿼리와 키 벡터를 통해 주의 점수를 계산하고, 이 차이를 통해 노이즈를 제거함.
- 이 방식은 주의 메커니즘을 통해 불필요한 정보에 대한 주의를 줄이고, 중요한 정보에 집중할 수 있게 만듦.
2.2 Overall Architecture
- DIFF Transformer는 여러 층을 쌓아 구성되며, 각 층은 차별적 주의 모듈과 피드포워드 네트워크로 구성됨.
- RMSNorm과 SwiGLU와 같은 최신 기술을 결합하여 성능을 최적화함.
3. Experiments
- DIFF Transformer는 다양한 언어 모델링 과제에서 기존 트랜스포머보다 우수한 성능을 보임.
- 모델 크기, 학습 토큰 수, 문맥 길이를 확장할 때도 성능 개선을 확인함.
3.1 Language Modeling Evaluation
- DIFF Transformer는 대형 언어 모델에서 기존 트랜스포머보다 더 나은 언어 모델링 성능을 달성함.
- 특히, 긴 문맥에서 중요한 정보를 더 잘 추출하는 능력을 보여줌.
3.2 Scalability Compared with Transformer
- DIFF Transformer는 더 적은 매개변수와 학습 토큰으로도 기존 트랜스포머와 유사한 성능을 냄.
- 파라미터 수와 학습 데이터 양을 줄이면서도 성능 저하 없이 확장 가능함.
3.3 Long-Context Evaluation
- DIFF Transformer는 긴 문맥에서 중요한 정보를 더 효과적으로 활용하며, 긴 문맥에서의 성능 저하를 줄임.
- 64K 길이의 문맥에서도 뛰어난 성능을 보임.
3.4 Key Information Retrieval
- DIFF Transformer는 복잡한 문맥에서 중요한 정보를 더 잘 검색하며, 주의 노이즈를 줄임.
- 다양한 문맥 길이에서도 우수한 성능을 유지함.
3.5 In-Context Learning
- DIFF Transformer는 in-context 학습에서 더 높은 정확도와 강인성을 보임.
- 순서 변화에도 성능이 덜 저하되며, 여러 샷 설정에서도 좋은 성능을 냄.
3.6 Contextual Hallucination Evaluation
- 질문 응답과 요약에서 DIFF Transformer는 기존 모델보다 헐루시네이션을 더 효과적으로 줄임.
- 모델이 문맥에서 정확한 정보를 추출하는 데 더 집중하도록 개선됨.
3.7 Activation Outliers Analysis
- DIFF Transformer는 모델 활성화 아웃라이어 문제를 줄이며, 더 효율적인 양자화를 가능하게 함.
- 활성화 값의 극단적인 변동을 줄여, 훈련 및 추론 중 더 안정적인 성능을 보장함.
3.8 Ablation Studies
- DIFF Transformer의 각 설계 요소에 대한 영향력을 평가한 결과, 차별적 주의 메커니즘이 성능에 크게 기여함.
- 다양한 초기화 전략에서도 성능이 일관되게 유지됨.
4. Conclusion
- DIFF Transformer는 트랜스포머의 한계를 극복하고, 중요한 정보에 더 잘 집중하도록 개선된 아키텍처임.
- 다양한 언어 모델링 과제에서 뛰어난 성능을 보이며, 대형 언어 모델 발전에 중요한 역할을 할 것으로 기대됨.
기타
저자의 소개글
트랜스포머는 관련 없는 문맥에 과도한 주의를 할당하는 경향이 있습니다. 이 연구에서는 중요한 문맥에 대한 주의를 증폭시키고 노이즈를 제거하는 Diff Transformer를 소개합니다. 구체적으로, 차별적 주의 메커니즘은 두 개의 별도 소프트맥스 주의 맵 간의 차이를 계산하여 주의 점수를 산출합니다. 이러한 차감 방식은 노이즈를 제거하고, 희소한 주의 패턴이 나타나도록 유도합니다. 언어 모델링에 대한 실험 결과, Diff Transformer는 모델 크기를 확장하거나 학습 토큰을 증가시키는 다양한 설정에서 기존 트랜스포머보다 더 우수한 성능을 보여주었습니다. 더욱 흥미로운 점은 Diff Transformer가 긴 문맥 모델링, 주요 정보 검색, 헐루시네이션 완화, in-context 학습, 활성화 아웃라이어 감소와 같은 실제 응용 분야에서 탁월한 이점을 제공한다는 것입니다. Diff Transformer는 관련 없는 문맥에 덜 영향을 받기 때문에 질문 응답 및 텍스트 요약에서 헐루시네이션을 완화할 수 있습니다. 또한, in-context 학습에서 Diff Transformer는 정확도를 높일 뿐만 아니라, 순서 변환에 대한 강인성도 향상시키며, 이는 오랜 시간 문제로 여겨졌던 강인성 문제를 해결하는 데 기여합니다. 이러한 결과는 Diff Transformer가 대형 언어 모델을 발전시키는 매우 효과적이고 유망한 아키텍처임을 보여줍니다.
다른 사람의 요약
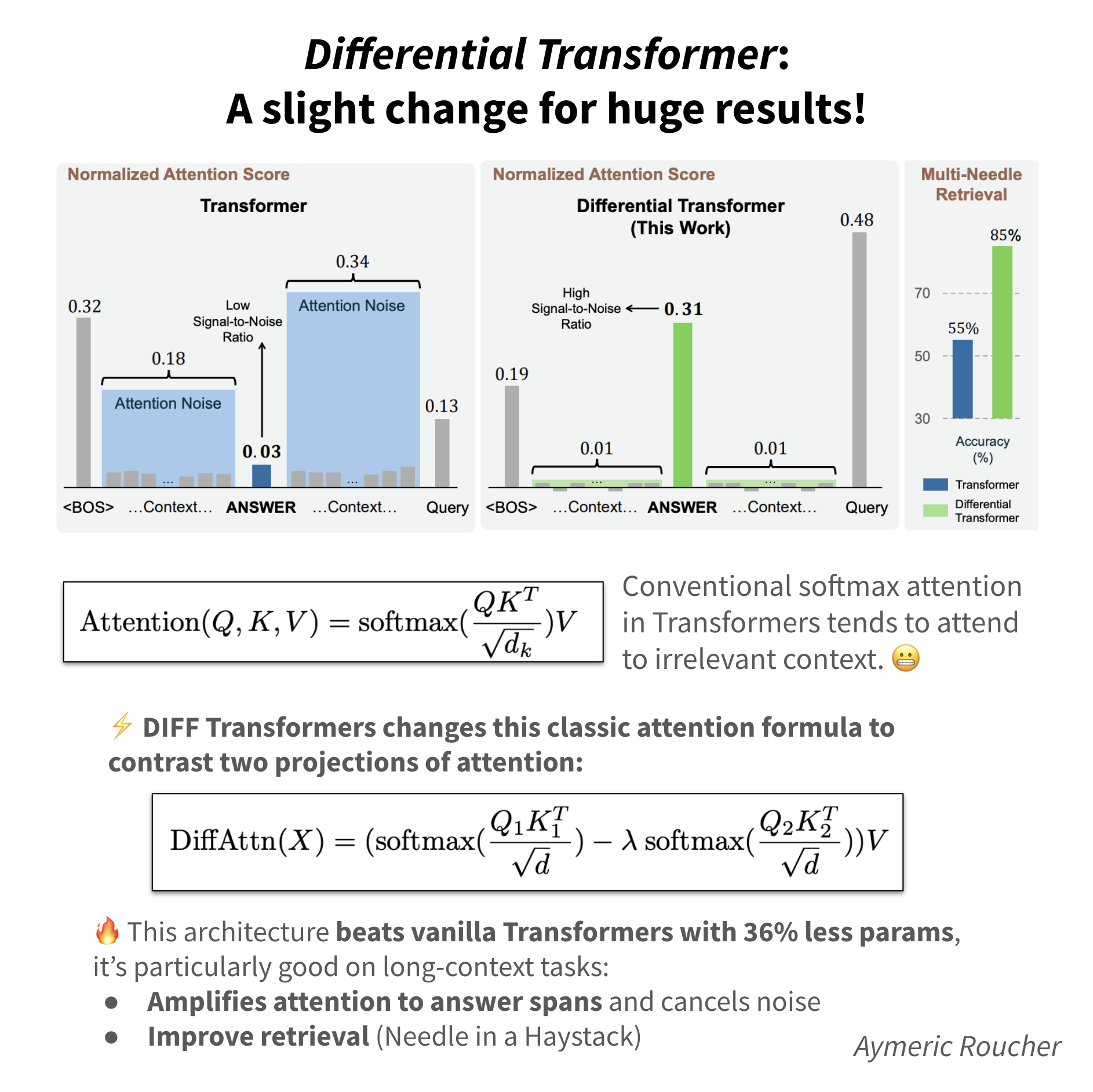
⚡️ 𝐌𝐨𝐬𝐭 𝐢𝐦𝐩𝐨𝐫𝐭𝐚𝐧𝐭 𝐛𝐫𝐞𝐚𝐤𝐭𝐡𝐫𝐨𝐮𝐠𝐡 𝐭𝐡𝐢𝐬 𝐦𝐨𝐧𝐭𝐡: 𝐃𝐢𝐟𝐟𝐞𝐫𝐞𝐧𝐭𝐢𝐚𝐥 𝐓𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐞𝐫 𝐯𝐚𝐬𝐭𝐥𝐲 𝐢𝐦𝐩𝐫𝐨𝐯𝐞𝐬 𝐚𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 ⇒ 𝐛𝐞𝐭𝐭𝐞𝐫 𝐫𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥 𝐚𝐧𝐝 𝐟𝐞𝐰𝐞𝐫 𝐡𝐚𝐥𝐥𝐮𝐜𝐢𝐧𝐚𝐭𝐢𝐨𝐧𝐬!
Thought that self-attention could not be improved anymore?
Microsoft researchers have dropped a novel “differential attention” mechanism that amplifies focus on relevant context while canceling out noise. It sounds like a free lunch, but it does really seem to vastly improve LLM performance!
𝗞𝗲𝘆 𝗶𝗻𝘀𝗶𝗴𝗵𝘁𝘀:
🧠 Differential attention computes the difference between two separate softmax attention maps, canceling out noise and promoting sparse attention patterns
🔥 DIFF Transformer outperforms standard Transformers while using 35-40% fewer parameters or training tokens
📏 Scales well to long contexts up to 64K tokens, leveraging increasing context length more effectively
🔎 Dramatically improves key information retrieval, enhancing in-context learning, and possibly reducing risk of hallucinations 🤯
🔢 Reduces activation outliers, potentially enabling lower-bit quantization without performance drop!
⚙️ Can be directly implemented using existing FlashAttention kernels
This new architecture could lead much more capable LLMs, with vastly improved strengths in long-context understanding and factual accuracy.
But they didn’t release weights on the Hub: let’s wait for the community to train the first open-weights DiffTransformer! 🚀