Training Language Models to Self-Correct via Reinforcement Learning
23 Oct 2024 |
Daily Paper
하루에 한 논문을 30분 안에 간단하게 살펴본 결과를 기록하는 포스트입니다.
논문을 살펴볼 때 ChatGPT의 도움을 적극적으로 받으며, 따라서 포스트에 잘못된 내용이나 오류가 있을 수 있습니다.
피드백이나 의견 있으시면 언제든지 연락주세요.
3줄 요약
- LLM은 다양한 문제를 훌륭하게 해결하지만, 자신의 답변에서 오류를 스스로 인식하고 수정하는 능력은 상대적으로 약함
- 학습 과정을 2단계(답변 생성 -> 답변 수정)으로 나누어서 학습하게 하여 자기수정(self-correct) 능력을 크게 향상
- 인간의 사고과정을 점점 따라가고 있는 듯한 느낌
논문 정보
- 논문 제목: Training Language Models to Self-Correct via Reinforcement Learning
- 저자: Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, Aleksandra Faust
- 소속: Google DeepMind, Equal Contribution, Randomly ordered via coin flip, Jointly supervised.
- 원문 링크: arXiv 링크
배경
- LLM은 다양한 문제를 훌륭하게 해결하지만, 그 과정에서 발생하는 오류를 스스로 인식하고 수정하는 능력은 상대적으로 약한 상태
- 수학적 추론, 코딩, 논리적 문제 해결과 같은 영역에서 매우 중요
- 기존에는 아래와 같은 시도들이 있었으나, 효과적이지 않았음
- 프롬프트 엔지니어링 : 의미있는 변화가 없었음
- 파인 튜닝 : 입력을 처리하는 별도 모델이 필요하거나, 수정 과정을 감독하는 teacher 모델이 필요
문제
- Distribution Shift (분포 불일치)
- 훈련 데이터와 실제 문제 해결 중 발생하는 오류의 차이로 인해 성능이 저하
- Behavior Collapse (행동 붕괴)
- 학습이 첫 번째 시도의 최적 응답을 생성하는 데 집중되고 두 번째 시도에서는 피상적인 수정 또는 수정이 전혀 이루어지지 않는 경우
SCoRe
- Self-Correction via Reinforcement Learning
- 대규모 언어 모델(LLM)이 외부 감독 없이 스스로 오류를 수정할 수 있도록 강화 학습(RL)을 사용한 새로운 접근법
학습 단계
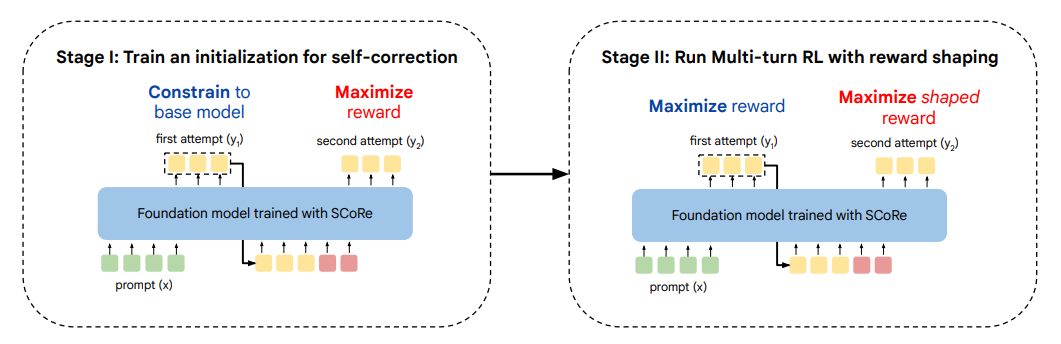
1단계: 단계별로 상관관계를 최소화하는 초기화 과정을 학습
- 기존 모델의 응답에서 너무 많이 동떨어지지 않으면서 2단계에서 잘 고칠 수 있는 답변을 생성하는 단계
- 비효율적이게 보일 수 있지만, 행동 붕괴(behavior collapse)가 발생하지 않도록 하기 위해서 꼭 필요함
- KL-발산(KL-divergence)을 이용하여 조정
2단계: 보상 형성을 적용한 다단계 강화 학습
- 1단계의 결과에서부터 시작하여 1단계와 2단계를 모두 최적화 함
- 강화학습의 보상에 단순히 정답과 가까운 정도 만을 보상으로 제공하는 것이 아니라, 1단계의 답변을 수정한 정도를 추가함
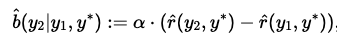
- 잘못된 1단계 답변을 제대로 고치면 양(+)의 보상
- 올바른 1단계 답변을 틀리게 고치면 음(-)의 보상
기타
- 필요시 위 단계를 반복하면서 Multi-Trun 학습
- 답변을 실시간으로 생성하며 온라인(online) 학습
특징
- 단순한 단일 모델 아키텍처
- 단일 모델이 자체적으로 오답 데이터를 생성하고 해당 문제를 오류를 인식하고 수정할 수 있도록 훈련
- 다양한 오답 데이터셋을 자체 생성하면서 분포 불일치 문제 해결
- 두 단계로 분리하여 학습흐며 행동 붕괴 방지
- 단순히 정답을 학습하는 것이 아닌 오류를 인식하고 수정하는 능력을 학습
성과
- 수학 및 코딩 문제에서 우수한 성능
- MATH 문제에서 15.6%, HumanEval 코딩 문제에서 9.1%의 자기 수정 성능 향상을 기록
Abstract
대규모 언어 모델(LLM)의 자기 수정(self-correction) 능력은 매우 바람직한 특성이지만, 현대의 LLM에서는 이러한 능력이 대체로 효과적이지 않다는 것이 반복적으로 밝혀졌습니다. 현재 자기 수정 능력을 훈련하는 방법들은 여러 모델을 사용하거나, 더 진보된 모델, 또는 추가적인 감독 형태에 의존하고 있습니다. 이러한 단점을 해결하기 위해, 우리는 오직 자체 생성 데이터만을 사용하여 LLM의 자기 수정 능력을 크게 향상시키는 다단계 온라인 강화 학습(RL) 접근법인 SCoRe를 개발했습니다. SCoRe를 구축하기 위해, 우리는 오프라인 모델이 생성한 수정 경로를 사용한 변형된 지도 학습 방식(SFT)이 자기 수정 행동을 주입하기에 충분하지 않다는 것을 먼저 보여줍니다. 특히, SFT 방식은 데이터 수집 정책이 만든 실수와 모델 자체의 응답 간의 분포 불일치로 인해 제대로 작동하지 않거나, 학습이 특정 수정 행동 모드에만 치우쳐 테스트 문제에서 자기 수정이 효과적이지 못한 경우가 발생합니다. SCoRe는 모델이 생성한 자체 수정 경로에서 학습하여 이러한 문제를 해결하고, 테스트 시에 효과적인 자기 수정 행동을 학습하도록 적절한 규제를 적용합니다. 이 규제 과정에는 행동 붕괴를 방지하기 위한 기본 모델에 대한 다단계 RL 초기화가 포함되며, 자기 수정을 증폭시키기 위한 보상 추가가 이어집니다. 우리는 Gemini 1.0 Pro 및 1.5 Flash 모델을 사용하여, SCoRe가 수학(MATH) 및 코딩(HumanEval) 문제에서 각각 15.6%와 9.1%의 성능 향상을 기록하며, 최첨단 자기 수정 성능을 달성했음을 확인했습니다.
목차 및 요약
1. 서론 (Introduction)
- 대규모 언어 모델(LLM)의 자기 수정 능력은 현재 매우 제한적이며, 이를 개선하기 위해 기존 방법들은 여러 모델이나 외부 감독에 의존했습니다.
- 본 논문은 이러한 문제를 해결하기 위해 강화 학습 기반의 SCoRe 접근법을 제안합니다.
2. 관련 연구 (Related Work)
- 자기 수정 및 강화 학습 관련 기존 연구들을 분석하고, LLM의 자기 수정 문제와 해결 방안을 다룬 다양한 접근법을 검토합니다.
- 특히, 강화 학습과 지도 학습의 차별점을 설명합니다.
3. 예비 지식 및 문제 설정 (Preliminaries and Problem Setup)
- 모델이 스스로 오류를 수정하는 과정의 구조와 문제 설정을 설명합니다. 특히, 다단계 강화 학습에서의 모델 학습 절차를 정의합니다.
4. 지도 학습 기반 접근법의 한계 (SFT on Self-Generated Data is Insufficient for Self-Correction)
- 지도 학습(SFT)을 기반으로 한 기존 자기 수정 접근법이 효과적이지 않은 이유를 분석합니다.
- 분포 불일치와 행동 붕괴 문제를 설명하고 그 한계를 보여줍니다.
5. SCoRe: 다단계 강화 학습을 통한 자기 수정 (SCoRe: Self-Correction via Multi-Turn Reinforcement Learning)
- 본 논문의 핵심인 SCoRe 접근법을 제안하며, 두 단계로 나누어 자기 수정 능력을 학습시키는 과정을 설명합니다.
- 첫 번째 단계는 초기화를, 두 번째 단계는 다단계 RL을 사용한 자기 수정 능력의 향상을 다룹니다.
6. 실험 및 결과 (Experiments)
- MATH 및 HumanEval 데이터셋을 활용한 SCoRe의 성능을 실험하고, 기존 모델과 비교하여 자기 수정 능력이 크게 향상된 결과를 제시합니다.
7. 결론 (Conclusion)
- SCoRe는 외부 감독 없이도 LLM의 자기 수정 성능을 크게 향상시키는 강화 학습 접근법입니다.
- 향후 연구에서는 더욱 복잡한 문제로 확장할 가능성을 제안합니다.
기타
- 참고 블로그 : 링크