1. Apache Parquet
15 Jan 2023 | Docs Apache Parquet 아파치 파케이
Docs 시리즈는 공식 Docs를 통해 기술을 올바르게 이해하는 시리즈 입니다.
- 원문
- Apache Parquet 공식 Docs - Parquet에 대한 전반적인 내용 및 안내
- parquet-foramt의 README.md - Parquet 파일의 포멧에 대한 프로젝트
- 위 두 링크를 제가 임의로 내용을 합쳐서 번역하였으며, 이해에 도움이 될 방향으로 정리하였습니다.
이번 글은 Docs 시리즈의 첫 시작이라 형식이나 구성이 완전하진 않습니다. 글의 시인성이 좀 떨어지는 것 같아 구성을 바꿀수도 있을 것 같습니다.
피드백이나 의견 있으시면 언제든지 연락주세요.
Apache Parquet
아파치 파케이(이하 파케이)는 하둡이나 데이터레이크 등 데이터를 오브젝트(=파일) 단위로 저장하는 방식에 적합한 파일 포맷입니다.
공식 Docs를 기반으로 파케이의 구조를 알고 특징을 깊이 이해하는 것이 이 글의 목적입니다.
1. 열 기반 저장방식
기본적으로 저희가 많이 보는 데이터의 저장 방식은 거의 행(Row) 기반 저장방식입니다. 파케이와 자주 비교되는 json 형식의 데이터를 살펴보겠습니다.
{"col_1":"value_1", "col_2":"value_2", ... , "col_n":"value_n"}
{"col_1":"value_1", "col_2":"value_2", ... , "col_n":"value_n"}
...
반면에 파케이는 데이터를 열 단위로 관리하고 있습니다. 실제로는 아래와 같이 저장되고 있진 않지만, 이해를 위해서 나타내자면 아래와 같습니다.
"col_1":["value_1", "value_2", ...]
"col_2":["value_1", "value_2", ...]
...
"col_n":["value_1", "value_2", ...]
열 기반 저장방식을 사용하면 특정 컬럼만 조회하는 상황에서 장점을 가집니다.
아래 select 문을 한번 볼까요? 전체 테이블에서 col_n 컬럼만 가져오는 간단한 쿼리입니다. (일부러 마지막 컬럼을 조회하는 상황을 가정했습니다)
select col_n from tb;
행 기반으로 저장된 위 json 예시를 보면, 아래와 같이 데이터를 읽어오겠죠
- 첫 번째 행을 읽는다
col_n을 찾는다.- 해당하는 값을 가져온다.
- 두 번째 행을 읽는다
col_n을 찾는다.- 해당하는 값을 가져온다.
- 모든 행에 대해 반복
열 기반으로 저장된 예시를 보면, 아래와 같이 데이터를 읽어올 겁니다.
col_n이 저장된 곳을 찾는다.- 읽어온다.
행 기반 저장방식에서는 특정 컬럼만 읽어올 때라도 모든 행을 다 접근해야 합니다. 하지만, 열 기반 저장방식에서는 특정 컬럼만 바로 읽어올 수가 있습니다.
이외에도 아래와 같은 장점을 가집니다.
- 특정 컬럼만 읽을 수 있어 디스크 IO가 적다.
- 컬럼 별로 데이터 타입이 동일하기 때문에 적합한 인코딩(ex. int32, IEEE 32/64 bit floating point values)을 선택할 수 있다.
- 컬럼 단위로 압축하면 데이터가 균일하므로 압축률이 좋다.
2. 메타 데이터
아래는 파케이 파일의 구조를 간략하게 나타낸 그림입니다.
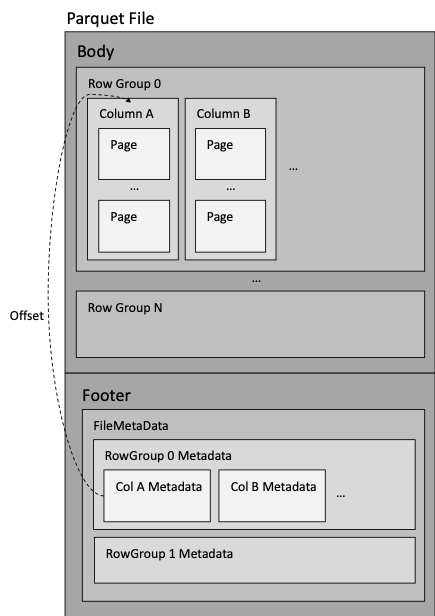
- 바디(Body)
- 데이터가 실제 저장되는 부분
- 공식적으로 Body라는 용어는 없고, 편의상 Footer에 대응되는 개념으로 이 글에서만 지정
- 행 그룹 (Row Group)
- 데이터를 행으로 나눈 논리적 파티션 (실제 보장되는 물리적 구조는 없음)
- 컬럼 청크 (또는 컬럼)으로 이루어져 있음
- 컬럼 청크 (Column Chunk)
- 특정 컬럼의 데이터를 가지고 있는 부분
- 컬럼 청크 레벨에서도 별도의 메타 데이터 및 통계 데이터를 가짐
- 페이지로 이루어져 있음
- 페이지
- 파케이에서 데이터를 압축하는 최소 단위
- 페이지는 다른 컴포넌트들과 다르게 메타데이터가 Footer에 있는게 아니라 데이터와 같이 있음
- 푸터(Footer)
- 해당 파일과 내부의 컴포넌트에 대한 메타 데이터가 저장되는 부분
- 파일 레벨 (FileMetaData)
- 행 그룹 레벨 (RowGroup)
- 컬럼 청크 레벨 (ColumnMetaData)
- 메타 데이터가 맨 끝에 있는 이유는, 파일을 한번만 쓰기 위해서 (single pass writing)
- 해당 파일과 내부의 컴포넌트에 대한 메타 데이터가 저장되는 부분
첫 번째 특징에서 특정 컬럼의 데이터만 선택적으로 가져올 수 있다고 하고, 방법에 대한 얘기는 하지 않았었는데요. 메타 데이터에 컬럼 구조와 실제 위치(Offset)이 적혀 있기 때문에 가능합니다.
실제 예시를 통해서 파케이의 메타 데이터에 실제로 어떤 정보를 가지고 있는지를 알아보겠습니다. 아래 예시에서 사용하는 데이터는 뉴욕의 택시 데이터의 통계정보이며, 여기에서 직접 다운로드 받을 수 있습니다.
import pyarrow.parquet as pq
file = pq.ParquetFile('./yellow_tripdata_2022-01.parquet')
print(file.metadata)
print(file.schema)
<pyarrow._parquet.FileMetaData object at 0x7fd3a1b5c050>
created_by: parquet-cpp-arrow version 7.0.0
num_columns: 19
num_rows: 2463931
num_row_groups: 1
format_version: 1.0
serialized_size: 10386
<pyarrow._parquet.ParquetSchema object at 0x7fcc939aecd0>
required group field_id=-1 schema {
optional int64 field_id=-1 VendorID;
optional int64 field_id=-1 tpep_pickup_datetime (...));
optional int64 field_id=-1 tpep_dropoff_datetime (...));
optional double field_id=-1 passenger_count;
...
optional double field_id=-1 congestion_surcharge;
optional double field_id=-1 airport_fee;
}
위 메타 데이터를 보면 아래와 같이 파일에 대한 많은 것을 알 수 있습니다. 예를 들어,
- 파일 포맷 버전(format_version) : 1.0
- 행 그룹 갯수(num_row_groups) : 1
- 행 갯수(num_rows) : 2463931
- 열 갯수(num_columns) : 19
- 스키마 정보
이런 메타 데이터 만으로도 처리할 수 있는 쿼리들이 많이 있습니다. 가장 대표적으로
select count(*) from yellow_tripdata;
위 쿼리는 메타데이터에서 num_rows만 스캔하면 바로 알 수 있습니다.
3. 통계 데이터
두 번째 특징에서는 파일 전체적인 메타데이터만 살펴보았는데요, 조금 더 자세하게 행그룹과 특정 컬럼의 메타데이터도 보곘습니다.
import pyarrow.parquet as pq
file = pq.ParquetFile('./yellow_tripdata_2022-01.parquet')
print(file.metadata.row_group(0))
print(file.metadata.row_group(0).column(3))
<pyarrow._parquet.RowGroupMetaData object at 0x7f8077154230>
num_columns: 19
num_rows: 2463931
total_byte_size: 66612116
<pyarrow._parquet.ColumnChunkMetaData object at 0x7f8077154770>
file_offset: 19912932
file_path:
physical_type: DOUBLE
num_values: 2463931
path_in_schema: passenger_count
is_stats_set: True
statistics:
<pyarrow._parquet.Statistics object at 0x7f8077188dd0>
has_min_max: True
min: -0.0
max: 9.0
null_count: 71503
distinct_count: 0
num_values: 2392428
physical_type: DOUBLE
logical_type: None
converted_type (legacy): NONE
compression: GZIP
encodings: ('PLAIN_DICTIONARY', 'PLAIN', 'RLE')
has_dictionary_page: True
dictionary_page_offset: 19424097
data_page_offset: 19424161
total_compressed_size: 488835
total_uncompressed_size: 1049330
여기에서 중요한 정보는 statistics입니다. 해당 데이터는 컬럼 청크가 실제로 가지고 있는 데이터의 통계 데이터를 가지고 있습니다. 위에 따르면 해당 컬럼(passenger_count)는 아래와 같은 특징을 갖고 있습니다.
- 타입(physical_type) : DOUBLE
- 최소값(min) : -0.0
- 최대값(max) : 9.0
- 값이 존재하는 / 존재하지 않는 행의 갯수 : 2392428 / 71503
위 데이터는 쓰임에 따라 굉장히 효율적으로 쓰일 수 있습니다. 예를 들어,
select * from yellow_tripdata where passenger_count >= 10;
passenger_count의 최대값이 9인데, 10 이상인 데이터를 조회하면 해당 데이터가 없다는 것을 데이터를 읽어보지도 않고 알 수 있습니다.
MySQL과 같은 RDB들은 성능 향상을 위해 들어오는 데이터를 타이트하게 관리하며, PK, 인덱스 등을 통해 통계자료도 저장하고 있습니다. 하지만, 데이터레이크와 같은 파일 기반 데이터저장소는 위와 같이 관리하는 것은 비효율적일 뿐만 아니라 취지에도 맞지 않습니다.
이런 상황에서 파케이는 내부에 메타데이터와 통계데이터를 가지고 있음으로써 위와 같은 단점을 효과적으로 상쇄시킬 수 있는 좋은 선택입니다. 이게 파케이가 데이터레이크 저장 형식의 대세가 된 이유지 않을까 싶네요.