3. Snappy
13 Dec 2024 | Docs Snappy 스내피
Docs 시리즈는 공식 Docs를 통해 기술을 올바르게 이해하는 시리즈 입니다.
아직 Docs 시리즈는 형식이나 구성이 완전하진 않습니다. 글의 시인성이 좀 떨어지는 것 같아 구성을 바꿀수도 있을 것 같습니다.
피드백이나 의견 있으시면 언제든지 연락주세요.
Snappy
Snappy(스내피)는 Google이 개발한 고성능 데이터 압축 알고리즘 및 라이브러리입니다.
요약
- 스내피의 목적은 "적당히 압축하되 속도가 빠르고 리소스 부담이 없는 압축방법"
- 실시간 데이터 처리, 로그 저장, 스트리밍 데이터 분석 등에서 널리 활용됨
- 속도가 빠른 이유는 해시테이블을 사용하기 때문
- 메모리를 많이 사용하지 않는 이유는 윈도우마다 해시테이블을 초기화하기 때문에
주요 특징
- 빠른 속도 (링크)
- 압축, 해제 속도 : 250MB/s, 500MB/s 이상
- 다른 알고리즘(LZO, LZF, QuickLZ 등) 대비 빠른 속도를 가짐
- 적당한 압축률 (vs. zlib)
- 일반 텍스트 : 1.5~1.7배 (zlib: 2.6~2.8배)
- HTML : 2~4배 (zlib: 3~7배)
- 낮은 CPU, 메모리 사용
- 해시테이블을 이용한 압축으로, 복잡한 연산을 필요로 하지 않음
- 윈도우 단위로 해시테이블을 초기화하여 너무 큰 메모리 사용 방지
- 안정성
- 몇 년 동안 Google의 프로덕션 환경에서 페타바이트 규모의 데이터를 안정적으로 압축 및 해제하였음
- 압축 해제시 손상되거나 악의적인 입력 데이터에 대해서도 충돌하지 않도록 설계되었음
- 오픈 소스
- BSD 유형의 라이선스를 따르는 무료 오픈 소스 소프트웨어
알고리즘
LZ77 알고리즘
스내피의 알고리즘은 LZ77 알고리즘에 기반을 두고 있습니다.
LZ77 알고리즘을 간단히 설명하자면, "앞에서 나온 내용을 재활용해서 쓰자" 입니다.
자세한 동작 원리는 아래와 같습니다.
- 인코딩의 시작 지점을 입력 데이터의 시작에 위치합니다
- 버퍼 사이즈만큼의 데이터를 읽습니다.
- 윈도우와 버퍼를 비교하여 가장 긴 일치하는 문자열을 찾습니다.
- 가장 긴 일치하는 문자열의 거리와 길이 (없을 경우 0), 그리고 다음 문자를 기록합니다.
- 길이+1만큼 인코딩 시작지점을 이동합니다.
- 데이터가 아직 남았다면 2번으로 이동합니다.
여기에서 윈도우와 버퍼의 개념이 등장합니다.
- 윈도우(window)
- 이전에 처리된 데이터의 일부를 저장하는 영역으로, 반복 패턴을 찾기 위해 검색되는 데이터의 범위
- LZ77 알고리즘에서는 슬라이딩 윈도우 방식을 택함
- 버퍼(buffer)
- 현재 처리중인 데이터의 일부를 저장하는 영역으로, 윈도우에 매칭될 영역
아래 예시를 보면 쉽게 이해할 수 있을거라 생각합니다.
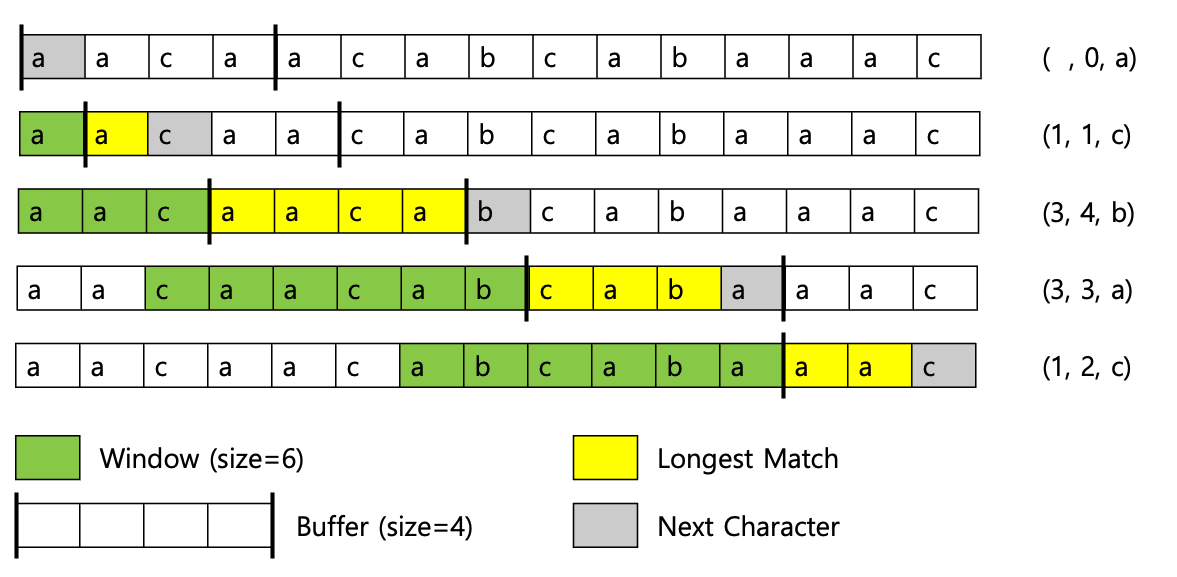 (이미지 출처 : 링크)
(이미지 출처 : 링크)
위 방식은 매우 효율적인 방식이지만, 매칭되는 문자열을 매번 찾아야 한다는 단점이 있습니다. 윈도우가 크면 클수록 매칭되는 문자열을 만날 확률이 높아지지만, 반대로 매칭하기 위한 시간은 늘어납니다.
Snappy 알고리즘
스내피 알고리즘은 LZ77 알고리즘에서 몇가지 개선사항이 있습니다.
첫번째로, 매칭되는 문자열을 찾을 때 해싱 테이블을 이용합니다.
버퍼에 있는 문자열을 해싱한 뒤, 해싱테이블에 저장하여 다음 문자열을 찾을 때 해당 정보를 이용합니다. 이렇게 함으로써 매칭 시간을 단축시켜 압축 시간을 줄일 수 있습니다.
두번째로, 스내피 알고리즘에서 윈도우는 해싱 테이블을 유지할 데이터 단위입니다.
LZ77에서는 가까운 이전 데이터를 봤기 때문에 이전 데이터를 슬라이딩하면서 움직였지만, 이제는 해싱 테이블을 사용하기 때문에 앞의 데이터를 볼 필요가 없습니다.
스내피 알고리즘에서는 윈도우 내에서만 해싱테이블을 유지하고, 다음 윈도우로 이동하면서 해싱 테이블을 초기화합니다. 이렇게 함으로써 해싱 테이블이 너무 커지는 것을 방지하고 불필요한 메모리 사용을 방지합니다.
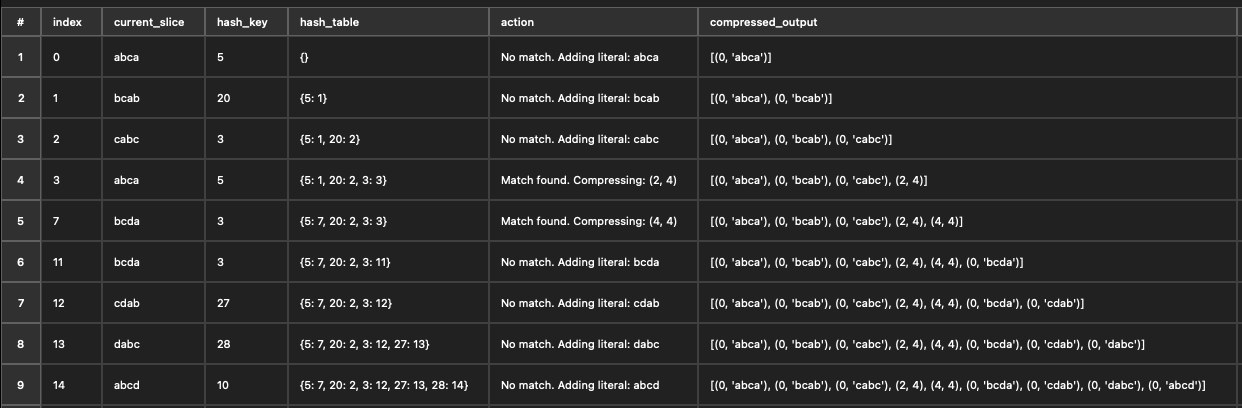
아래 파이썬 코드는 스내피 압축 알고리즘이 어떻게 동작하는지 간단하게 설명합니다. 실제 스내피는 좀 더 복잡한 동작이 있지만, 아래 예시로 충분할 거라 생각됩니다.
# 간단한 해시 테이블 매칭 구현
def find_matches(data, window_size=32):
hash_table = {}
compressed = []
i = 0
while i < len(data) - 4: # 최소 4바이트 블록
# 현재 슬라이스
current_slice = data[i:i+4]
# 해시 계산 (간단히 해시 함수 사용)
hash_key = hash(current_slice) % window_size
# 해시 테이블에서 매칭 검색
if hash_key in hash_table and hash_table[hash_key] != i:
# 거리와 길이를 기록
distance = i - hash_table[hash_key]
compressed.append((distance, len(current_slice)))
i += len(current_slice)
else:
# 새로 추가
compressed.append((0, current_slice))
i += 1
# 해시 테이블 업데이트
hash_table[hash_key] = i
return compressed
# 데이터 압축
data = "abcabcabcdabcdabcde"
compressed_data = find_matches(data)
print("Compressed Data:", compressed_data)
아래 테이블은 위 예시가 어떻게 동작하는지 보여줍니다.